
Tabular Foundation Models: A New Default for Tabular Machine Learning?
From XGBoost, LightGBM, CatBoost to TabPFN, CARTE, and the next wave of tabular AI


From Gradient-Boosted Decision Trees to Foundation Models
When you work with tabular data, especially when there are from a few thousand to a few tens of millions of rows, THE default solution has been clear for almost a decade: Gradient-Boosted Decision Trees (GBDTs), especially the three musketeers: XGBoost, LightGBM, CatBoost.
What GBDTs Get Right, and Where They Hurt
GBDTs are great! They are:
Fast and competitive on benchmarks,
Robust across many real-world datasets,
Surrounded by a mature ecosystem: SHAP, AutoML stacks, production integrations, and more.
They have been around since 2016-2018, which in modern AI era, feels like ancient history. We’re living in a time where new state-of-the-art AI models appear every month (if not week), a ten-year-old method still dominating an entire domain is remarkable.
And yet, that dominance is not really a problem. If it’s not broken, there is no urgent need to fix it.
The real issue is that classic GBDTs, despite their performance, come with structural limitations. The three structural drawbacks below show up again and again in practice:
No real transfer learning: for each task, you train a new model from scratch. Knowledge does not really transfer from one dataset to another. Imagine your restaurant hires a chef who is brilliant at making chocolate pie. One day you ask him to make brownies. You would expect him to adapt his chocolate pie experience and get to a good brownie quickly, right? But no, the chef has to learn and start from cratch like a complete beginner. => That’s how GBDTs work.
Hard to inject external knowledge: encoding domain knowledge, ontologies, or external relationships into GBSTs (for example, “broccoli and carrots are both vegetables, chicken is meat”) is not easy and often requires complex feature engineering.
Awkward model updates: using GBDTs mean that everytime new data arrive, we have to face a difficult choice: either we ignore the new data or we retrain the model. Both options have drawbacks. If we ignore the new data, we lose insights from latest information. If we retrain the model, well, we face two other problems: i) retraining can be costly (in time and compute), and ii) the new model can behave very differently from the previous one, which is risky in regulated or business-critical settings.
A Decade of Deep Learning on Tabular Data
Over the last ten years, there has been a continuous effort to bring deep learning to tables. Many architectures have been proposed, and surveys [1, 2] show that the story has been more nuanced than “deep learning wins everywhere.” Up until recently, new deep models such as ModernNCA, TabM, and RealMLP have started to rival tree ensembles.
However, for industrial projects, GBDTs have remained the go-to approach, both in production and in Kaggle competitions.
This was true until very recently.
Enter Tabular Foundation Models
Now there is a new “sheriff in town”: Tabular Foundation Models (TFMs).
Foundation models are not a new idea. Since the late 2010s, we have seen BERT-series and GPT-style models in NLP; Vision Transformers in computer vision; Large multimodal models that ingest text, image, video, and more. The pattern is similar:
Pre-train a large model on huge, generic datasets to learn “general knowledge”.
Adapt it to downstream tasks (via in-context learning, prompting, or light fine-tuning).
This has been spectacularly successful in text and images.
But not for tabular data!
Foundation models for tabular data lagged behind for two main reasons:
Data availability: tabular data in industry is everywhere but mostly private. There is no “ImageNet of tables” easily available for massive pre-training.
Heterogeneous structure: Each dataset has its own schema, feature types, distributions, and semantics. This makes it hard to directly reuse the techniques that worked well for images and text.
But everything has changed!
TFMs emerged in 2022 and rose to prominence by 2025:
TabPFN introduced a transformer-based tabular foundation model trained purely on synthetic data, framing learning as in-context learning over tables.
TabPFN v2 (and later TabPFN-2.5) scaled this idea and set new state-of-the-art results on many tabular benchmarks, including TabArena.
Other TFMs emerged, such as Mitra, LimiX, CARTE, and TARTE, each pushing a different angle of the foundation-model story for tabular data.
Broadly, current TFM approaches can be grouped into two main schools.
School 1 – The TabPFN Family: Synthetic Priors and In-Context Learning
The first school is the TabPFN school: TabPFN (v1/v2/2.5), TabICL, Mitra, LimiX, and related models.
Core idea: learn to learn from synthetic data
These models use Structural Causal Models (SCMs) and similar generative mechanisms to create massive synthetic tabular datasets. The TFM is then pre-trained on these synthetic tasks to approximate Bayesian inference “in general”:
Each synthetic dataset defines a mapping from features to labels.
The model sees many such datasets and learns a generic learning algorithm encoded in its weights.
Crucially, the model never sees real benchmark data during pre-training, which helps avoid data leakage.
In-context learning for tables
At inference time, the workflow is very different from traditional pipelines. You feed both:
A support set (training rows with labels), and
A query set (rows whose labels you want to predict).
The model processes all of this jointly in a single forward pass and outputs the predictions for the query set (see Fig. 1).
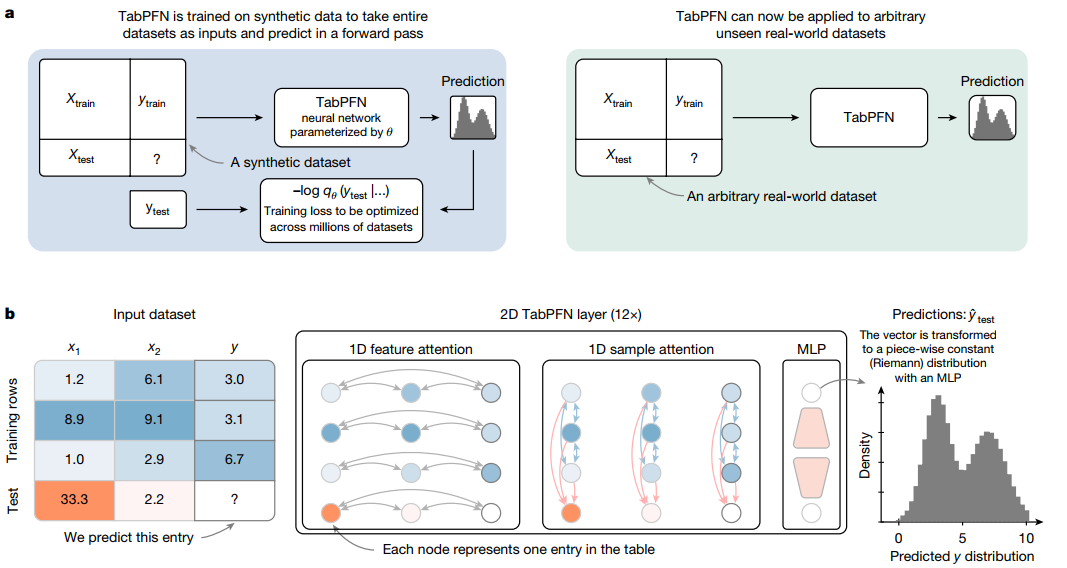
This is In-Context Learning (ICL) for tabular data:
No gradient updates on the downstream task,
No explicit hyperparameter tuning,
A single forward pass that adapts to the new dataset.
TabPFN v2, for example, is pre-trained on 130 million synthetic datasets and, at inference time, can outperform tuned tree-based ensembles even when they are given hours of hyperparameter search. TabPFN-2.5 pushes this further. It scales to around 50,000 rows and up to 2,000 features. The model achieves state-of-the-art performance on TabArena and other benchmarks in a single forward pass! PriorLabs also reports that TabPFN Scaling mode removes the row-limit constraint and outperforms GBDTs as well as large AutoML ensembles..
Other models like Mitra, TabICL, and LimiX extend the TabPFN idea by mixing different synthetic priors (e.g. LimiX), using better transformer architecture for faster inference (TabICL).
In short, the TabPFN school gives us:
A way to overcome the lack of shared real tabular data by relying on synthetic priors
A fast, training-free inference procedure that acts like a generic learner for new datasets
School 2 – Semantic Representation: CARTE, TARTE, and Knowledge Graphs
The second school is the Semantic representation school, illustrated by models like CARTE and TARTE.
Motivation: make tables understand what entities are
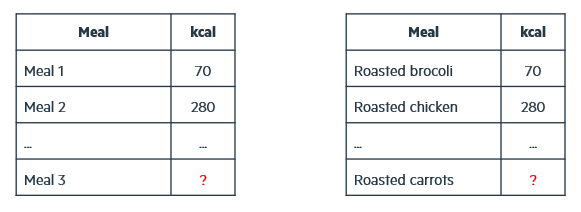
Suppose you are predicting the calories of meals:
In training, you have roasted chicken and roasted broccoli.
At test time, you see roasted carrots.
As humans, we know that carrots are a vegetable, like broccoli; and chicken is meat, typically more calorie-dense. So, without seeing carrots in training, you would guess that carrot calories should be closer to broccoli than to chicken.
A standard tabular model (including many TFMs) typically encodes these as arbitrary category IDs: meal 1, meal 2, meal 3. It then tries to infer the calories of meal 3 given observations of meal 1 and meal 2, without knowing what those products actually are (Fig. 2). That is a very hard problem.
CARTE and TARTE try to fix this by injecting world knowledge into the model.
How they do it
These models use text encoders (such as language models) and knowledge graphs like YAGO to represent entities and column names in a shared semantic space.
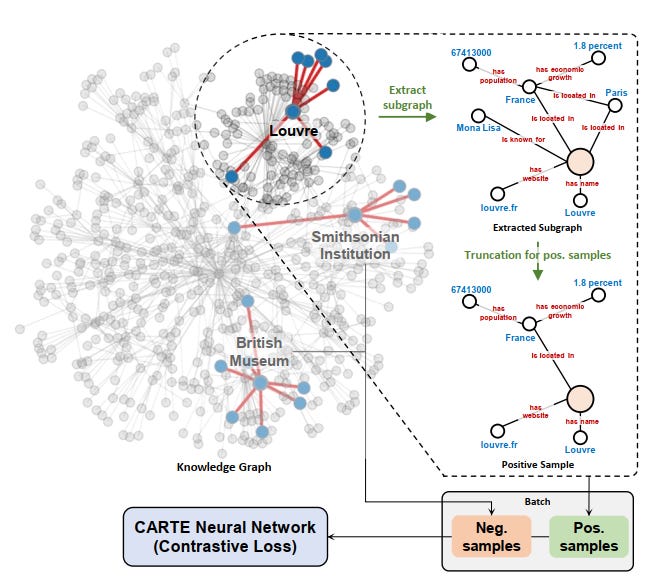
In that space, broccoli and carrot live in the vegetables zone, while chicken lives in a different one (meats). The model can then reason in a way that better aligns with common sense.
CARTE represents each table row as a small graph and applies a graph transformer to learn contextual representations of entries, columns, and their relationships. TARTE builds on these ideas and trains a knowledge-enhanced foundation model for tables, using relational data and knowledge bases to pre-train representations that can be reused across tasks.
This semantic school:
Partially addresses the data availability problem by leveraging public knowledge graphs and relational data.
Tackles the knowledge-injection problem by explicitly embedding entities in a knowledge-rich representation.
It is currently less mature than the TabPFN school in terms of leaderboard performance. One of the explaination is that many real tabular datasets have been collected with a “GBDT mindset”: they are mostly numerical and categorical features, often little or no free text, and limited use of structured knowledge. So the full benefit of semantic representations may only appear as we start collecting richer tabular datasets with text fields, identifiers linking to external graphs, and other modalities.
But conceptually, CARTE and TARTE are an innovative approach, and this chool may be crucial for multimodal and knowledge-heavy tasks.
Impact
What Changes for Practitioners?
“Ok that’s nice, but what does it mean for us - practitioners?”
TFMs help us squeeze some last % of accuracy.
However, the main impact will live in how we run projects.
A different project loop
A typical data-science project with GBDTs looks like this:
Step1 Framing: define objectives, KPIs, and evaluation protocol.
Step 2 Data collection: collect data from different sources.
Step 3 Exploratory Data Analysis (EDA): to understand distributions, leakage, feature quality, and so on.
Step 4 Modeling loop: feature engineering, shortlist and educated guess of candidate models, run some light tests (run the model with a few hypeparaters optimisation- HPO trials).
Step 5 Fine-tuning: fine tune the most promising options. This step take time, often overnight or over days depending on the size of the data.
Step 6 Analysis of results: analyze the resulat, and iterate by going back to step 2 (or even step 1)
Step 7 Deployment and monitoring
Because each serious GBDT experiment can take hours or days, we usually test only a limited number of options, and use fast “light tests” to decide which options will be fine-tuned. That causes problems because:
The light tests do not always correlate perfectly with full-blown tuning.
Experience frequent interruptions in our train of thought while models train.
With TFMs like TabPFN v2, inference is effectively “instant” on small-to-medium datasets (seconds). Hence you can test many more modeling options (different feature sets, targets, problem framings) in a single session. Default settings often yield near–state-of-the-art performance without hyperparameter tuning. This changes the ”division of labor”: machines handle the heavy lifting of pattern discovery, while practitioners can invest more effort in better framing, higher-quality data collection, richer error analysis, business interpretationn, and stakeholder communication. It also boosts individual productivity: your thought process is not constantly interrupted by long training jobs.
Natively multimodal tabular machine learning
TFMs are neural-network-based and operate on vector representations of features. That means you can:
Plug in text embedders for textual fields (for example, product descriptions, free-text notes, clinical narratives).
Plug in image embedders for imaging or document snapshots.
Concatenate these embeddings with traditional numeric and categorical features and feed them into the same TFM.
In principle, this gives a cleaner path toward multimodal tabular machine learning, which is harder to achieve elegantly with classic GBDTs.
Model refresh and lifecycle
As mentioned earlier, with traditional GBDTs, new data leads to a hard choice: ignore it and keep an outdated model, or retrain and risk behavior shifts, plus pay the compute and engineering cost.
With TFMs, you typically feed the latest training data (or a carefully chosen subset) at inference time. There is no retraining in the traditional sense: the model learns the task on the fly from its support set, so you always condition on the most recent information, with stable behavior encoded in the foundation model itself.
This does not magically solve every MLOps issue (you still need monitoring, drift detection, and governance), but it changes where the complexity lives: from “train many bespoke models” to “curate good support sets and maintain one or a few powerful TFMs”.
What Changes for Researchers?
For the research community, TFMs are already reshaping the landscape.
New base learners
For years, decision trees were the default base learners for boosting and bagging. TFMs, especially TabPFN-style models, offer a neural alternative that can be used as either standalone predictors ir components inside ensembles (for example, TabPFN as a base learner)
This opens up a fresh design space for hybrid tree–transformer systems.
New explainability challenges
The current ecosystem around trees, especially TreeSHAP/SHAP. It works extremely well because it exploits tree structure. For TFMs, we will need:
New attribution methods tuned to set-and-sequence-based architectures.
Ways to explain in-context learning behavior.
Unifying the two schools
Today, the TabPFN school and the semantic-representation school are largely separate. Promising directions include:
Using semantic encoders (text or knowledge-graph embedders) as front-ends for TabPFN-style in-context learning models
Training two-phase TFMs:
Phase 1: large-scale synthetic pre-training (in the spirit of TabPFN)
Phase 2: semantic fine-tuning on real relational data and knowledge graphs (in the spirit of CARTE and TARTE)
This could give us models that are both: strong learners from pure tabular structure, and aware of external world knowledge and semantics
Outlook
Tabular foundation models are still in their early days. We are not seeing a (reported) clear performance plateau yet. Scaling in data and parameters still seems to pay off. New models like TabICL, TARTE, and others are broadening the design space.
The tabular domain has been “the last bastion of classical machine learning”. With tabular foundation models, that bastion is finally being seriously challenged, not just by another model, but by a different way of thinking about learning from tables.
The future is bright!
 | A guest post by
|